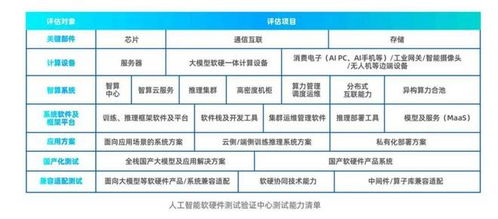
隨著人工智能(AI)和機器學習(ML)技術的快速崛起,許多軟件組織正積極推動敏捷開發(fā)轉型,以提升響應市場變化的能力。在AI和ML基礎軟件開發(fā)項目中,敏捷開發(fā)方法的應用卻常常受到限制或完全被忽略。這背后有多重原因值得深入探討。
AI和ML項目的不確定性極高。與傳統(tǒng)的軟件開發(fā)不同,AI項目往往涉及探索性研究、數(shù)據(jù)質量的不確定性以及模型性能的不可預測性。敏捷開發(fā)強調迭代和快速交付,但在AI項目中,前期可能需要大量時間進行數(shù)據(jù)清洗、特征工程和模型實驗,這些活動難以被精確分解成短周期的沖刺。當團隊面臨未知的技術挑戰(zhàn)時,固定的迭代節(jié)奏可能導致壓力過大,甚至影響項目方向。
AI基礎軟件開發(fā)對專業(yè)知識和基礎設施的依賴性強。這類項目通常需要深厚的數(shù)據(jù)科學和算法背景,以及高性能計算資源。敏捷開發(fā)強調跨職能團隊和通用技能,但在AI項目中,團隊成員可能需要高度專業(yè)化,溝通和協(xié)作的復雜度增加。基礎設施設置(如GPU集群、數(shù)據(jù)管道)往往需要較長的準備時間,這與敏捷的快速啟動理念存在沖突。
需求定義的模糊性是一個關鍵因素。在傳統(tǒng)軟件中,用戶故事可以清晰描述功能需求;但在AI項目中,需求可能涉及“提高模型準確率”或“優(yōu)化推理速度”等抽象目標,很難在迭代中具體化。客戶或利益相關者可能難以準確表達AI能力預期,導致敏捷開發(fā)中的優(yōu)先級排序和驗收標準設定困難。
文化和組織障礙也阻礙了敏捷開發(fā)在AI項目中的應用。許多組織在轉型敏捷時,可能尚未適應AI項目的獨特性。例如,管理層可能更傾向于采用瀑布模型,以便更好地控制研發(fā)預算和風險。數(shù)據(jù)科學家和工程師之間可能存在工作流程差異,數(shù)據(jù)科學家習慣于實驗驅動的方法,而敏捷開發(fā)強調代碼交付和持續(xù)集成,這需要額外的協(xié)調努力。
敏捷開發(fā)工具和實踐在AI領域的適應性不足。例如,Scrum或Kanban板可能無法有效跟蹤模型實驗、數(shù)據(jù)版本或超參數(shù)調優(yōu)過程。盡管有些團隊嘗試擴展敏捷框架(如DataOps或MLOps),但這些方法仍處于成熟階段,缺乏廣泛的標準支持。
雖然敏捷開發(fā)在傳統(tǒng)軟件開發(fā)中表現(xiàn)出色,但在AI和ML基礎軟件開發(fā)中,其應用面臨獨特挑戰(zhàn)。組織在進行敏捷轉型時,需要針對AI項目的特性進行調整,例如引入更靈活的計劃周期、加強跨學科協(xié)作,并整合專門工具。通過融合敏捷原則與AI研發(fā)實踐,才能更有效地推動創(chuàng)新,避免錯過AI時代的機遇。