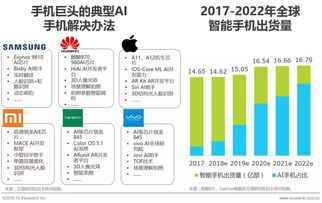
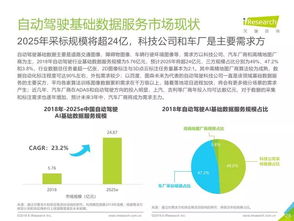
中國人工智能在應用層和算法層面取得了舉世矚目的成就,從人臉識別、智能推薦到自動駕駛,眾多領域走在了世界前列。在支撐這一切繁榮的底層——人工智能基礎軟件開發領域,卻面臨著嚴峻的“卡脖子”風險。這已成為制約中國人工智能產業從“應用領先”邁向“系統領先”和“生態領先”的關鍵瓶頸。
所謂“人工智能基礎軟件”,主要指支撐人工智能模型開發、訓練、部署和管理的核心軟件棧與工具鏈。其核心通常包括:
- 深度學習框架:如TensorFlow(谷歌)、PyTorch(Meta),是構建和訓練AI模型的“操作系統”。
- 底層計算庫與編譯器:如CUDA(英偉達)、ROCm(AMD),是連接硬件與框架,釋放算力性能的關鍵。
- 模型庫與開發工具:提供預訓練模型、自動化工具和集成開發環境。
目前,全球AI基礎軟件生態幾乎由美國科技巨頭主導。TensorFlow和PyTorch已成為全球AI研究和工業界的“事實標準”,而英偉達憑借其CUDA生態與硬件深度綁定,構筑了極高的壁壘。中國企業在開發尖端AI應用或大模型時,嚴重依賴這些國外基礎軟件。這種依賴帶來了多重風險:
- 技術斷供風險:在極端情況下,框架、核心庫的授權或更新可能受限,直接導致研發與生產活動停滯。
- 生態鎖定風險:一旦技術路線綁定,遷移成本極高。整個產業的工具習慣、人才培養體系都圍繞國外生態建立,形成路徑依賴。
- 安全與可控性風險:底層軟件可能存在的“后門”或數據泄漏隱患,對國家關鍵領域的AI應用構成潛在威脅。
- 創新天花板:基于他人的地基建房,難以在底層架構和軟硬協同上進行顛覆式創新,始終處于技術價值鏈的追隨者位置。
面對挑戰,中國產業界、學術界與政府已積極行動起來,尋求破局之道:
- 自主研發,構建國產框架體系:百度飛槳(PaddlePaddle)、華為MindSpore、清華大學計圖(Jittor)等國產深度學習框架已取得長足進步。其中,飛槳已發展成為功能全面、開發者社區活躍的國內領先平臺,致力于打造更符合中國產業需求的開發體驗和工具鏈。
- 軟硬協同,突破算力瓶頸:在面臨高端AI芯片獲取困難的國內芯片企業(如華為昇騰、寒武紀等)正加速推進自主AI計算架構。其核心挑戰在于構建能與CUDA生態競爭力相媲美的、繁榮的軟件棧和開發者生態,實現從硬件到應用的全棧自主。
- 開源共建,匯聚創新力量:積極參與并主導國際開源項目,同時大力建設本土開源社區。通過開源協作,降低開發門檻,吸引全球開發者,加速技術迭代與生態成熟。
- 政策引導與生態培育:國家通過重大科技項目、產業政策引導資源向基礎軟件傾斜。鼓勵產學研合作,加強基礎人才培養,尤其是在系統軟件、編譯技術等“冷板凳”領域。
- 場景驅動,以應用反哺基礎:利用中國豐富的應用場景和海量數據優勢,在自動駕駛、工業智能、科學計算等特定領域,深度優化國產基礎軟件,形成差異化優勢,實現從“可用”到“好用”的跨越。
突破人工智能基礎軟件的“卡脖子”困境,非一朝一夕之功,而是一場需要戰略定力、持續投入和開放協作的“持久戰”。它要求我們:
- 摒棄“速勝論”幻想:基礎軟件生態建設需要時間積累,必須尊重技術規律,耐得住寂寞。
- 堅持“自主”與“開放”并行:在堅定推進自主創新的必須保持與全球開源社區和先進技術的互動,避免閉門造車。
- 構建差異化價值:國產基礎軟件不能僅僅是替代品,更應結合中國超大規模市場與特色產業需求,解決實際痛點,創造獨特價值。
中國人工智能的下一程,不僅是算法模型的競賽,更是基礎軟件與根技術的較量。只有筑牢自主可控的軟件地基,才能支撐起人工智能大廈的持續創新與安全穩健,最終實現從技術應用大國到基礎創新強國的歷史性跨越。